|
Con
l'annuncio di IBM i 7.1 Tecnologia Refresh (TR) 9 e IBM i 7.2
Tecnologia Refresh (TR) 1, IBM sta condividendo la notizia di ciò che è
nuovo e migliorato. Il focus sul TR e la PTF Gruppo TR merita la vostra attenzione, ma non è parte del mio messaggio. Quello
che spero si capisce già che è DB2 per i miglioramenti vengono
rilasciati sulla stessa cadenza, come miglioramenti TR e la
distribuzione del software è in forma di PTF Gruppo DB2 (SF99701 per 7.1
e SF99702 per 7.2). L'asporto è semplice, come mostrato in Figura 1: sempre aggiornati e sarete ricompensati con funzionalità nuove e migliorate.
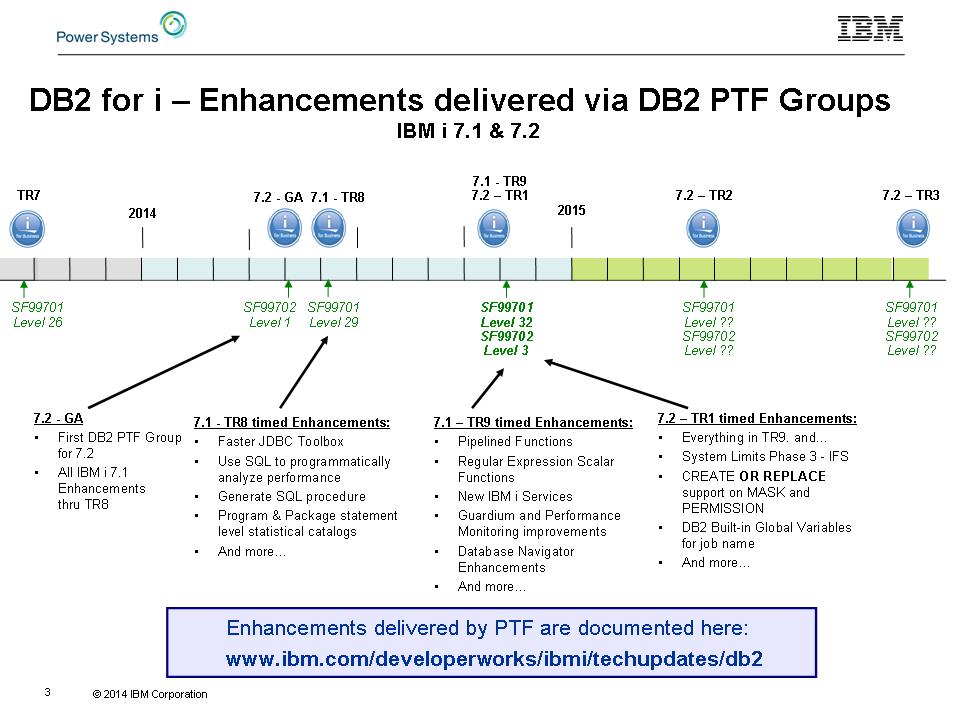
Figura 1: Questo è il DB2 per il miglioramento i timeline.
Cosa c'è di nuovo in DB2 for i Plenty Ma io riassumere con questa lista?!:
- Le nuove funzionalità di programmazione SQL
- Le nuove funzionalità di query SQL
- Nuovi servizi IBM i
Nuove funzionalità di SQL Programming
Il patrimonio della piattaforma IBM i è soluzioni applicative per l'elaborazione aziendale. Abbiamo ancora Abbracciamo l'obiettivo di consentire ai nostri fornitori di soluzioni per avere successo. In questo spirito, abbiamo aggiunto diversi miglioramenti di programmazione SQL.
Funzioni Tabella pipeline
Una funzione di tabella pipeline è un 100% puro SQL alternativa ad una funzione tabella definita dall'utente esterno (UDTF). Se stai dicendo a te stesso, "Hey, abbiamo già SQL UDTFs," siete sulla strada giusta. UDTFs SQL non pipeline restituiscono risultati attraverso la specificazione di una query sulla dichiarazione RETURN. Che cosa fare se non si può costruire una singola query che fornisce i risultati desiderati? Prima
di funzioni di pipeline, l'unica soluzione era quella di costruire il
proprio programma esterno programma / servizio e quindi creare un UDTF
esterno per consentirgli di essere richiamato. Anche
se non impossibile, è necessario sopportare gestione del codice
sorgente, un processo di generazione e un processo di distribuzione,
gestione delle autorizzazioni, e altro ancora. Per alcuni i clienti IBM, i passaggi sopra perché questa soluzione da un non-starter.
Una funzione pipeline si basa su l'istruzione PIPE SQL per restituire una riga di dati dal UDTF. Il motore SQL Query (SQE) utilizza una strada UDTF invocazione ben viaggiato per ripetere la richiesta di righe da restituire. Il programmatore UDTF pone in atto la logica che guida la tubazione di righe. Supporto PIPE è robusto, con valori, NULL, e le espressioni accettati come input. PIPE è una dichiarazione di controllo. Esso
restituisce la riga specificata per il motore di query e, quando gli
viene chiesto per la riga successiva, continua l'esecuzione con
l'istruzione SQL seguente il tubo. Se
il UDTF esaurisce istruzioni eseguibili o chiama l'istruzione SQL
RETURN, il motore di query osserva una condizione di end-of-file.
Codifica una funzione pipeline è facile (e divertente). Il codice di esempio riportato di seguito illustra la struttura di base.
Con pochissime eccezioni, un'istruzione SQL può fare riferimento a un solo database. Come si vede in questo esempio, una funzione pipeline può essere utilizzato per offuscare questa restrizione. L'invoker della funzione riceverà i risultati che sono stati raccolti da molti database. Utilizzare
le funzioni di pipeline per ottenere il controllo runtime dei risultati
restituiti, gestire e superare le condizioni di errore, o piegare le
regole di ciò che è possibile con SQL.
Esempio 1: Pipelined funzione tavolo recupero dei risultati provenienti da diversi database
CREATE OR REPLACE FUNCTION Group_check (P_PTF_GROUP_NAME VARCHAR (7))
RETURNS TABLE (V_PTF_GROUP_NAME CHAR (7),
V_PTF_GROUP_DESCRIPTION VARCHAR (100),
V_LEVEL_DETAIL CLOB (1K))
Linguaggio SQL
Inizio
DICHIARARE SkipIt INTEGER;
DICHIARARE TARGET_RDB VARCHAR (128);
DICHIARARE v_PTF_GROUP_NAME CHAR (7);
DICHIARARE v_PTF_GROUP_DESCRIPTION VARCHAR (100);
DICHIARARE v_PTF_GROUP_LEVEL INTEGER;
Dichiarare CONTINUA gestore per SQLEXCEPTION
Inizio
PIPE (NULL, NULL, TARGET_RDB CONCAT 'non è accessibile');
SET SkipIt = 1;
Fine;
SET (TARGET_RDB, SkipIt, v_PTF_GROUP_LEVEL) = ('lpdac710', 0, NULL);
SELEZIONA PTF_GROUP_NAME, PTF_GROUP_DESCRIPTION, PTF_GROUP_LEVEL
IN v_PTF_GROUP_NAME, v_PTF_GROUP_DESCRIPTION, v_PTF_GROUP_LEVEL
FROM WHERE lpdac710.QSYS2.GROUP_PTF_INFO P_PTF_GROUP_NAME = PTF_GROUP_NAME E PTF_GROUP_STATUS = ORDINE 'INSTALLATO' DA PTF_GROUP_LEVEL DESC
FETCH FIRST 1 solo le righe;
IF (SkipIt = 0 E v_PTF_GROUP_LEVEL IS NOT NULL) THEN
PIPE (v_PTF_GROUP_NAME, v_PTF_GROUP_DESCRIPTION,
TARGET_RDB CONCAT 'ha livello' CONCAT
inferiore (v_PTF_GROUP_LEVEL) CONCAT 'APPLICATA');
END IF;
SET (TARGET_RDB, SkipIt, v_PTF_GROUP_LEVEL) = ('MysteryMachine', 0, NULL);
SELEZIONA PTF_GROUP_NAME, PTF_GROUP_DESCRIPTION, PTF_GROUP_LEVEL
IN v_PTF_GROUP_NAME, v_PTF_GROUP_DESCRIPTION, v_PTF_GROUP_LEVEL
FROM WHERE MysteryMachine.QSYS2.GROUP_PTF_INFO P_PTF_GROUP_NAME = PTF_GROUP_NAME E PTF_GROUP_STATUS = ORDINE 'INSTALLATO' DA PTF_GROUP_LEVEL DESC
FETCH FIRST 1 solo le righe;
IF (SkipIt = 0 E v_PTF_GROUP_LEVEL IS NOT NULL) THEN
PIPE (v_PTF_GROUP_NAME, v_PTF_GROUP_DESCRIPTION,
TARGET_RDB CONCAT 'ha livello' CONCAT
inferiore (v_PTF_GROUP_LEVEL) CONCAT 'APPLICATA');
END IF;
Di ritorno;
Fine;
SELECT * FROM TABLE (Group_check ('SF99701')) A;
Nuovo DB2 for i Built-in variabili globali
Una variabile incorporato è una variabile definita e gestita dal database. Le tue istruzioni SQL possono fare riferimento a esso da nessuna parte che un nome di colonna è permesso. DB2
for i ha la responsabilità per il valore all'interno della variabile
globale, e gli utenti non sono autorizzati a modificare il valore della
variabile.
Queste variabili esistono solo in IBM i 7.2.
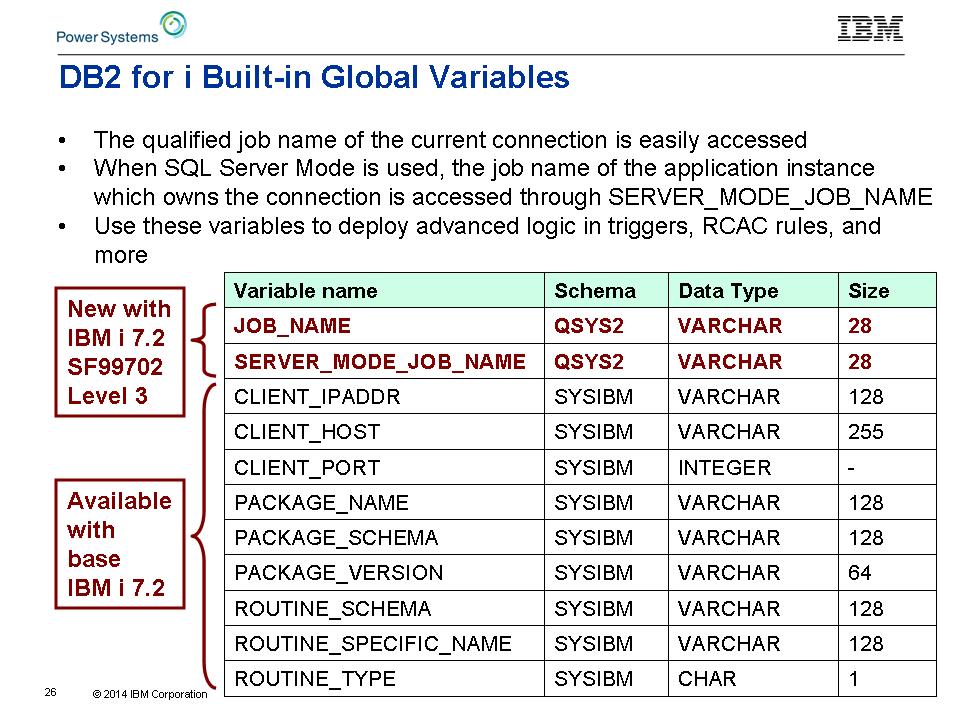
Figura 2: DB2 for i fornisce questi built-in variabili globali.
Abbiamo
altri miglioramenti di programmazione SQL, come il supporto migliorato
per il debug, la comprensione messaggi di errore SQL, e altro ancora. Alla fine di questo articolo, ho puntatori ai dettagli.
Questo
è un posto decente per dire che usiamo costi, rischi, e il valore
client per determinare quando fornire un miglioramento del database di
IBM esistente i rilasci del sistema operativo. Alcuni dei miglioramenti sono anche previsti per IBM i 6.1, dove non esiste la tecnologia TR. Ricordate, la PTF Gruppo DB2 è il carosello di cavalcare in questo carnevale.
Nuove funzionalità di SQL query
Non abbiamo mai smettere di investire nel nostro sostegno query. L'industria del database è sommerso di idee di miglioramento e le tecnologie emergenti. Grazie
agli sforzi instancabili della famiglia DB2 e DB2 per i Chief Architect
Mark J. Anderson, scegliamo con cura i miglioramenti di query in grado
di fornire il maggior impatto per i nostri clienti.
Espressioni regolari (GREP tuo DB2 per i dati)
Supporto alle espressioni regolari offre un modo nuovo ed emozionante per trovare i dati. (Psst ... trovare dati è un argomento abbastanza importante per qualsiasi database.) Il predicato REGEXP_LIKE può essere aggiunto a clausole WHERE per migliorare la selezione di righe. Quattro nuove funzioni REGEXP_ xxxx aggiungono il supporto complementare. Query
basate su espressioni regolari soddisfano le aspettative di completo
supporto per la lingua nazionale IBM i clienti utilizzando i servizi
forniti dalla International Components for Unicode (ICU) in IBM i Option
Base 39.
Figura 3 presenta una panoramica del nuovo supporto. I libri di riferimento per SQL 7.1 e 7.2 sono stati aggiornati per tutto il nuovo supporto SQL. La documentazione include la tabella "caratteri di controllo espressione regolari", che si estende su tre pagine. Inutile dire che, c'è un'abbondanza di flessibilità nei modelli di ricerca che è possibile creare.
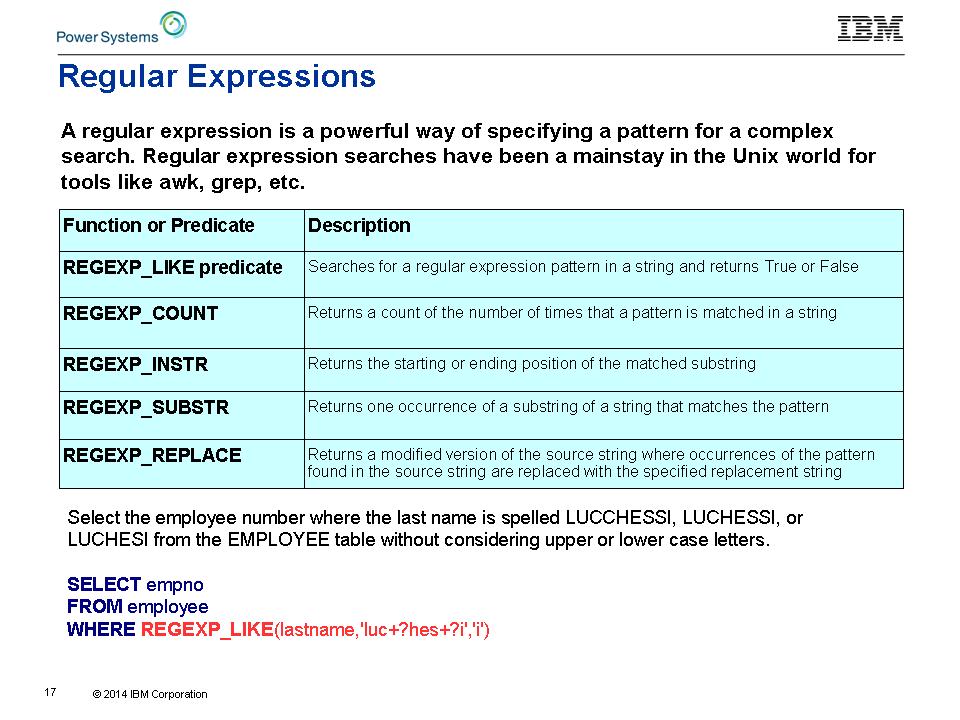
Figura 3: utilizzare espressioni regolari per la potente funzionalità di ricerca.
Anche in questo caso, un esempio illustrerà il nuovo supporto. In questo esempio, non vediamo alcun uso del predicato REGEXP_LIKE. Mentre può essere tipico di utilizzare il predicato e funzioni sulla stessa query, non c'è alcun obbligo in tal senso.
Questo
esempio mostra come le espressioni regolari possono essere usati per
trovare ed estrarre i riferimenti del sito web da un tweet o un testo. L'esempio comprende la sistemazione per i nomi di siti web liberamente formate e tra maiuscole e minuscole.
Esempio 2: Uso di espressioni regolari per estrarre i riferimenti del sito web
CREATE OR REPLACE FUNCTION FindHits (v_search_string CLOB (1M),
varchar v_pattern (32000))
RETURNS TABLE (website_reference varchar (512))
Linguaggio SQL
Inizio
DICHIARARE V_Count INTEGER;
DICHIARARE LOOPVAR INTEGER DEFAULT 0;
SET V_Count = REGEXP_COUNT (v_search_string, v_pattern, 1, 'i');
SE v_pattern IS NULL o la lunghezza (v_pattern) = 0 THEN
SET v_pattern = '(\ w + \.) + ((Org) | (com) | (gov) | (edu))';
END IF;
MENTRE LOOPVAR <V_Count DO
SET LOOPVAR = LOOPVAR + 1;
PIPE (REGEXP_SUBSTR (v_search_string, v_pattern, 1, LOOPVAR, 'i'));
END WHILE;
Di ritorno;
Fine;
SELECT
* FROM TABLE (FindHits ('Siete interessati a uno qualsiasi di questi
collegi:?. Isu.EDU o www.umn.Edu Potremmo anche visitare WWW.wisc.edu se
abbiamo tempo')) A;
Abbiamo anche esteso il nostro supporto query per includere nuove funzioni incorporate (BIF) per i dati di riempimento. Le funzioni LPAD e RPAD includono controlli programmatore oltre la lunghezza e pad carattere (s). Tutti gli ingressi possono essere derivati ??in fase di esecuzione attraverso l'uso di espressioni. Mentre
la logica dell'applicazione può certamente essere scritta per
manipolare i dati per soddisfare i requisiti di reporting di business,
speriamo che i nostri utenti a trovare questi nuovi DB2 BIFs
vantaggiosa.
Nuove IBM i Servizi
Negli
ultimi anni, il DB2 for i team ha iniziato a esternare IBM specifiche
per i dettagli del sistema operativo tramite cataloghi di database e
UDTFs. Se
non avete visto questi servizi, che valgono una sbirciatina perché
forniscono una nuova opzione per risolvere in modo efficiente i
requisiti di business. Le
informazioni deriva quando viene eseguita una query, e la query SQL
Engine (SQE) può essere usato per selezionare, gruppo, ordine, contare,
analizzare e trasformare i dati in forme utili. Documentiamo questi servizi in prestazioni del database e l'ottimizzazione delle query libro. Anche se questo può sembrare una strana casa, sono ufficialmente documentati, e ora si capisce dove guardare.
Nuovi cataloghi
Persone Database amano cataloghi. Cataloghi
tradizionali sono tabelle fisiche che contengono i dettagli necessari
per comprendere le relazioni tra i costrutti di database. IBM i servizi sono forniti anche tramite cataloghi di database. Come ho già detto, i dati restituiti sulla query viene estratto e restituiti al punto di esecuzione della query. Abbiamo tre nuovi cataloghi:
- QSYS2 / JOURNAL_INFO - Caratteristiche e stato di riviste locali e remoti
- QSYS2 / LIBRARY_LIST_INFO - lista Biblioteca particolare per il lavoro di esecuzione della query
- QSYS2 / REPLY_LIST_INFO - risposta Systemwide dettagli dell'elenco
Questi
cataloghi possono essere utilizzati per ottenere la gestione dei
sistemi migliori e per risolvere i problemi di business in modo più
efficiente.
Nuovo UDTF
Persone di database anche l'amore UDTFs. Stiamo fornendo un nuovo servizio IBM i, sotto forma di un UDTF. Il JOBLOG_INFO () UDTF dovrebbe essere una gradita aggiunta a molti tipi di utenti. Il
carattere commerciale (*) può essere passato per indicare che il
registro del processo corrente deve essere restituito, o un lavoro di
destinazione può essere specificato. Pensate a tutte quelle volte che hai bisogno di vedere un log di lavoro, ma era stato cancellato. Questo servizio rende mai così semplice per catturare i dettagli necessari. Ci sono altre applicazioni per questo servizio, ma lascio che per un'altra volta.
- QSYS2 / JOBLOG_INFO (qualificato-job-name) - messaggi joblog sono consumati e restituito sotto forma di una tabella SQL.
Qualcosa di inaspettato
Nello
spirito di mostrare come sia facile legare DB2 insieme disparato per i
tecnologie per realizzare qualcosa di utile, abbiamo aggiunto la visione
/ GROUP_PTF_CURRENCY SYSTOOLS. Questo punto di vista utilizza un nuovo feed XML fornito dall'organizzazione IBM preventiva Servizio Pianificazione (PSP). Il
feed contiene una descrizione up-to-date dei gruppi PTF ei pacchetti
CUM forniti da IBM, i loro livelli di servizio più recenti, e la data in
cui sono stati aggiornati da IBM.
La vista GROUP_PTF_CURRENCY utilizza il DB2 for i HTTP funzione di supporto per l'accesso e consumare il feed XML. Successivamente, la funzione XMLTable () viene utilizzata per la transizione dei dati XML in una forma relazionale. Infine,
la forma relazionale dei dati di IBM è paragonato al dettaglio sulla
partizione interrogando il catalogo QSYS2 / GROUP_PTF_INFO.
I
risultati di una query di esempio sono mostrati in Figura 4 Abbiamo
deciso di costruire questo al fine di migliorare la gestione dei sistemi
per IBM i clienti. Abbiamo anche sperato che questo servizio potrebbe stimolare la creatività e l'azione all'interno della comunità IBM i. Ci devono essere altre buone idee per servizi di questo genere. Lo schema SYSTOOLS è dove DB2 per utensili i navi ed esempi.
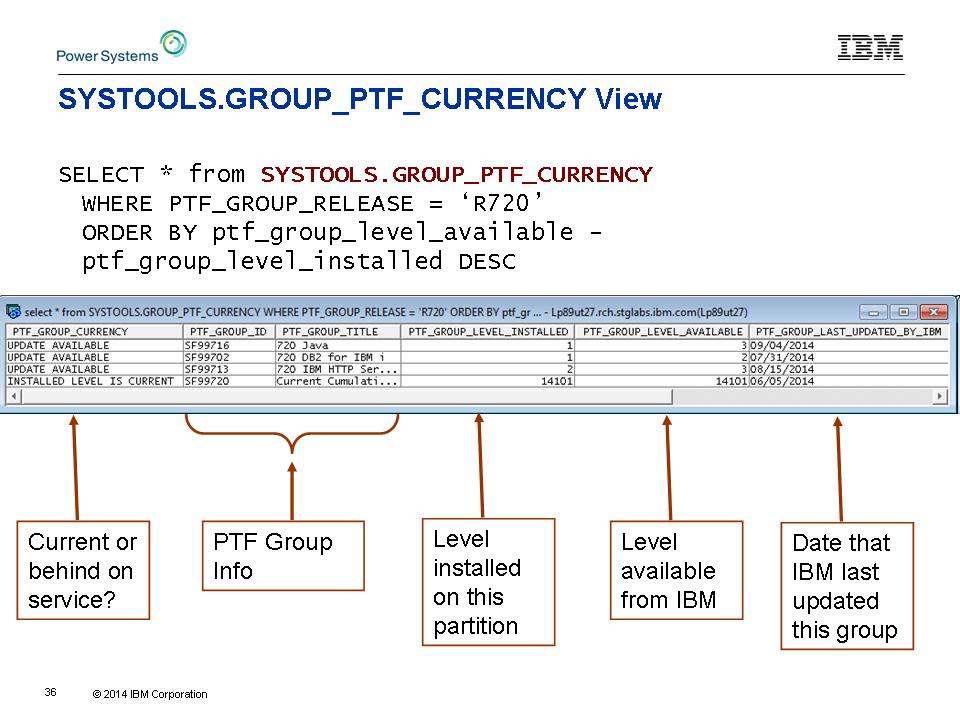
Figura 4: Utilizzare la vista / GROUP_PTF_CURRENCY SYSTOOLS.
On Your Way
Questo articolo ha toccato solo un sottoinsieme dei miglioramenti. Visita le seguenti pagine di destinazione per scoprire il set completo di miglioramenti e materiali tecnici relativi:
·
Poiché i segnali carnevale Barker che "lo show è finito," raccogliere i vostri dispositivi e riprendere iper-tasking. Grazie
per la vostra attenzione, e non vedo l'ora di sentire il vostro
feedback su questi miglioramenti e qualsiasi altra cosa vorresti vedere
costruita dal DB2 for i squadra.
|


